In the past 24 hours, frontier AI has delivered major leaps in multimodal image generation, open-source workflow tools, and agentic systems. From OpenAI’s reasoning-powered GPT Image 2.0 to rapid ComfyUI integrations and new open multimodal models, today’s AI advancements 2026 highlight the blistering pace of cutting edge AI news. Whether you track latest AI breakthroughs in video generation or ComfyUI news, these developments are reshaping how creators, researchers, and developers build with frontier AI models.
OpenAI Unleashes GPT Image 2.0: Reasoning-First Image Generation Redefines the Frontier
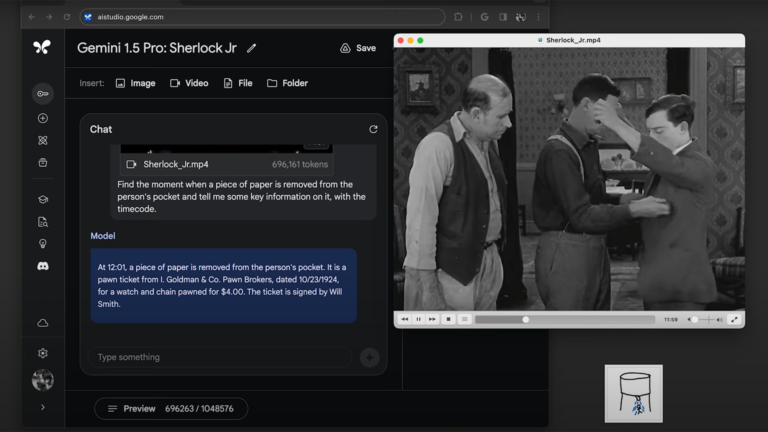
OpenAI dropped ChatGPT Images 2.0 (also referred to as GPT Image 2.0), a major upgrade that moves beyond one-shot generation. The model now plans compositions, self-checks outputs, and iterates for precision—delivering accurate text rendering, complex charts, scientific diagrams, and multilingual visuals that rival professional design tools.
![AINews] OpenAI launches GPT-Image-2 - Latent.Space](https://substackcdn.com/image/fetch/$s_!Y-b3!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fd187fe49-1184-477d-84b8-cbe7d502356e_2188x1604.png)
AINews] OpenAI launches GPT-Image-2 – Latent.Space
This isn’t just prettier pictures; it’s a step toward truly intelligent multimodal systems. Users report near-perfect text in UI mockups, infographics, and data visualizations—long a pain point for earlier image models. Early demos shared across X show the model handling aspect ratios up to 2K resolutions with native web-search integration for real-time context.
This release cements OpenAI’s lead in frontier image generation while accelerating competition in the “AI advancements” space.

OpenAI releases GPT-Image-2: Designers’ livelihoods may really be at risk. | PANews
ComfyUI Latest Updates: Native GPT Image 2.0 Support and Video Generation Breakthroughs
ComfyUI enthusiasts woke up to fresh partner-node integrations for OpenAI’s GPT Image 2.0, plus continued momentum on video pipelines. Recent GitHub commits (as recent as 4 hours ago) fixed Veo 3.0 4K handling and added standalone LTXV audio VAEs, while the community site highlights native Wan2.1 FLF2V support for stunning 720p video creation.
ComfyUI Integrates OpenAI’s Latest Image Generation Model: GPT-Image-1 – ComfyUI.org
These ComfyUI latest updates make the modular graph-based interface even more powerful for frontier AI models. Creators can now chain reasoning image nodes directly into video workflows, enabling end-to-end pipelines that were impossible yesterday. The open-source community’s day-one support continues to make ComfyUI the go-to for advanced model experimentation.
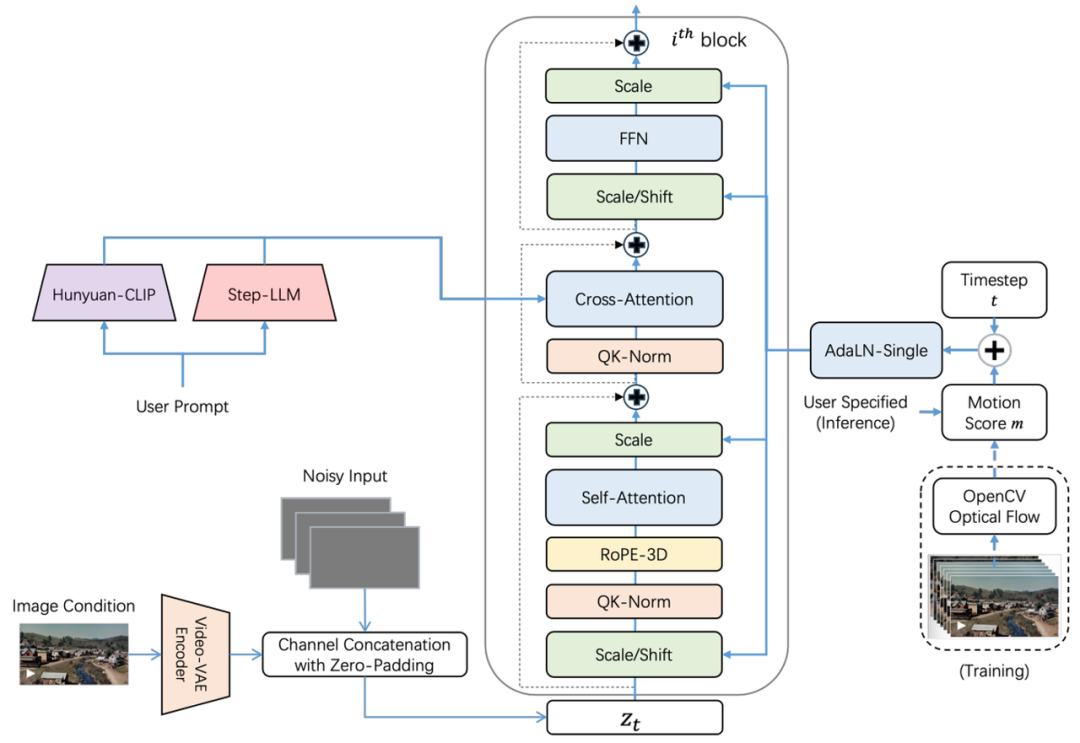
Unlocking the Power of Multimodal AI: Jieyue Xingchen’s Step-Video-TI2V Model Revolutionizes Image-to-Video Generation – ComfyUI.org
Source: ComfyUI.org news and GitHub commits (April 22, 2026)
Google Rolls Out Gemma 4: Efficient Open Multimodal Models Hit the Scene
Google DeepMind quietly pushed Gemma 4 templates into the wild—four variants ranging from tiny E2B (Raspberry Pi-capable) to the 31B dense flagship. The 26B-A4B Mixture-of-Experts model delivers near-frontier performance at the speed of far smaller models, with native multimodal (text + image) handling, 256K context, and 140+ language support.

Comprehensive interpretation of Google Gemma 4: 4 open-source models, Apache 2.0 license, and 6 core upgrades – Apiyi.com Blog
Under Apache 2.0 licensing, these frontier AI models are instantly runnable on Hugging Face, Ollama, and consumer hardware. Benchmarks show massive gains over Gemma 3 in math, code, and multimodal reasoning—perfect for developers building agentic AI workflows on a budget.
Source: Google DeepMind / X announcements (April 21–22, 2026)
Anthropic Previews Claude Mythos: Cybersecurity-Focused Frontier Model Heads to Government
Anthropic unveiled Claude Mythos, its latest flagship with built-in cybersecurity capabilities, and made it available to the U.S. government ahead of broader release. The model emphasizes dynamic safety, real-time violation detection, and advanced reasoning—key for agentic AI deployments in high-stakes environments.

Anthropic Releases Claude Mythos Preview with Cybersecurity Capabilities but Withholds Public Access – InfoQ
While public details remain limited, early signals point to Constitutional 2.0 safety upgrades that let agents self-correct during autonomous tasks. This move underscores growing collaboration between frontier labs and public institutions on responsible AI.
Source: U.S. Senator statements and InfoQ coverage (April 21, 2026)
Open-Source Video & Cinema Tools Surge: From Higgsfield to Full AI Production Studios
The open-source community didn’t sit idle. A new self-hosted AI cinema studio repo (MIT-licensed, 200+ models) surfaced, offering production-grade lip-sync, text-to-cinematic video, camera controls, and full image-to-video pipelines. Early stars on GitHub signal this could democratize high-end video generation overnight.

OpenAI backs first AI feature film
Combined with ComfyUI’s Wan2.1 and Veo updates, the barrier to professional-grade AI video is collapsing. These tools align perfectly with the broader shift toward agentic multimodal systems that don’t just generate—they plan, iterate, and produce.
Source: X community posts and repo activity (April 22, 2026)
Agentic AI & Research Momentum: New arXiv Papers on Emotion, Multi-Agent Systems
Fresh arXiv submissions (April 22) explore how emotion shapes LLM and agent behavior, alongside case-adaptive multi-agent deliberation for clinical prediction. These papers signal the next layer of frontier AI: systems that don’t just reason but understand internal states and collaborate autonomously.
While not flashy model drops, they provide the theoretical backbone for tomorrow’s agentic breakthroughs and reinforce why open research remains vital to AI advancements.
Why Today Matters for Cutting-Edge AI News Followers
The convergence of reasoning image models, instant ComfyUI support, efficient open multimodal releases, and safety-first frontier systems shows 2026 is the year agentic and multimodal AI move from prototype to production. Whether you’re building with ComfyUI latest updates, experimenting with new AI model releases, or tracking AI frontier developments, the past 24 hours delivered tools and research that will power the next wave of innovation.
Stay tuned for more daily cutting-edge AI updates.
The images used in this article are sourced from publicly available channels on the internet. They are used solely for the purposes of news commentary, visual illustration, and explanatory reference, and do not constitute commercial use. The author of this article does not own the copyright to these images and makes no claim to any rights over them. If any copyright issues arise regarding these images, please contact the article’s author, and we will promptly address the matter or remove the relevant content.