The AI frontier in early May 2026 continues its relentless pace, with multimodal and agentic systems dominating the spotlight. As we cross into the second quarter of the year, the convergence of native video understanding/generation, enhanced reasoning architectures, and tool-using agents marks a pivotal shift from generative chatbots toward truly autonomous, world-modeling AI.
This past 24 hours highlighted a significant leak pointing to Google’s next leap in unified multimodal capabilities. Such developments underscore broader trends: scaling laws are evolving toward efficiency in post-training (RLVR and synthetic data), native multimodality is becoming table stakes for frontier models, and agentic workflows are maturing from experimental to production-ready. These innovations promise transformative impacts across creative industries, scientific discovery, and autonomous systems, yet they also intensify challenges around compute demands, evaluation rigor, and safe deployment. Looking ahead, 2026 appears set for “omni” models that seamlessly blend text, image, video, and action in persistent environments.

Google’s Gemini Omni Testing: A Potential Unified Video Generation Powerhouse
A major highlight from the past day is the leak of a new UI string in Gemini’s video generation interface referencing “Powered by Omni.” This appears tied to an evolution beyond current Veo 3.1, potentially representing Google’s push toward a true omni-modal model capable of native video output alongside other modalities.
Technically, such a system likely builds on transformer-based diffusion or hybrid architectures with cross-attention mechanisms for conditioning on text, reference images, and temporal consistency. Veo 3.1 already excels at 4K output, native audio synchronization, object insertion, and physics-aware generation. Omni could integrate these into a single foundation model with improved long-horizon coherence and interactive editing—key for “world models” that maintain scene persistence.

Real-world impact includes democratizing high-end video production for filmmakers, marketers, and educators, slashing costs while enabling rapid iteration. Development prospects point to Google I/O 2026 as a launchpad, where Omni might outperform competitors in consistency and controllability. Challenges remain in hallucinated physics, copyright concerns with training data, and energy efficiency at scale. Forward-looking, this accelerates toward agentic video agents that can simulate and edit dynamic scenes autonomously. (Sources: Recent leaks reported on testingcatalog.com and X discussions, May 2, 2026)
Advancements in Agentic AI Architectures and Tool Integration
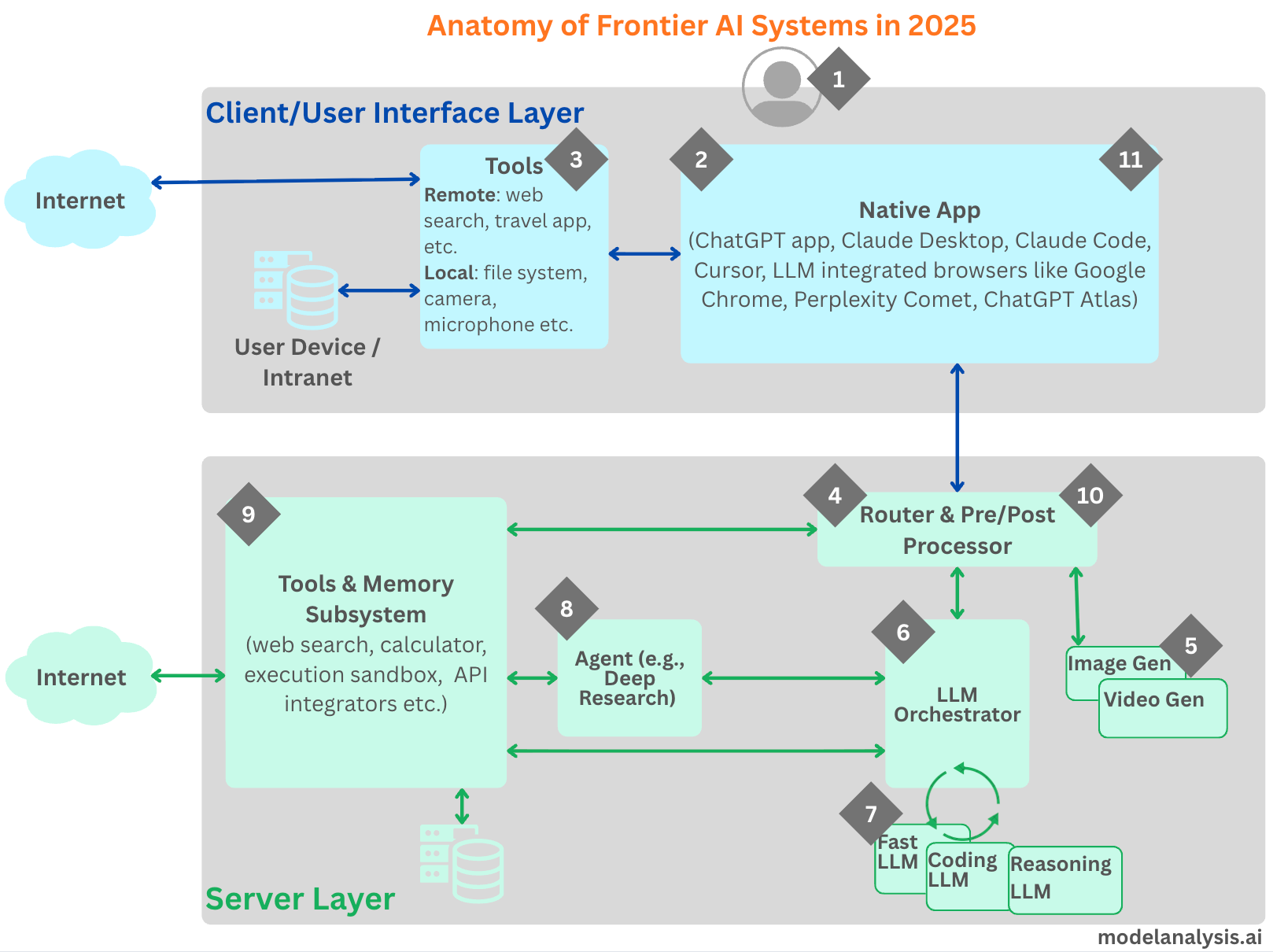
Parallel to video frontiers, agentic systems—AI that can plan, reason, use tools, and act over extended horizons—saw continued momentum in open discussions and incremental releases. Frameworks emphasize shared memory, multi-agent collaboration, and robust orchestration layers integrating LLMs with external APIs and environments.
These architectures typically feature a central LLM orchestrator routing between specialized modules (fast vs. slow reasoning, coding specialists) and tool subsystems. Recent open-source pushes, including efficient coding-focused models suitable for agent workflows, enhance local deployment and reduce latency.
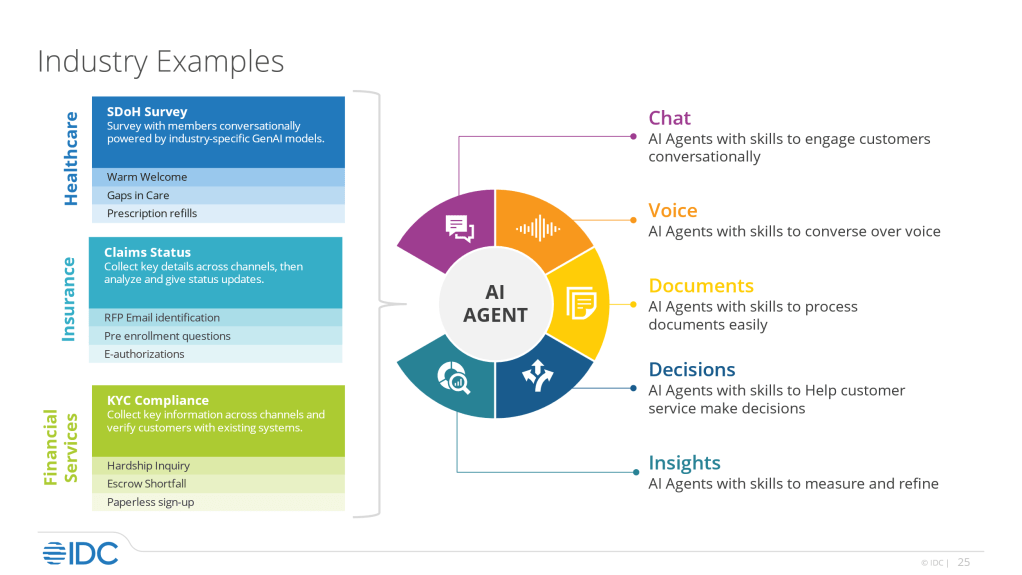
Impacts span software engineering (autonomous codebases), scientific simulation, and enterprise automation. Prospects include better state management to prevent “agent-caused outages” and improved multi-agent handoff protocols. Challenges involve alignment under distribution shift, security of tool use, and evaluation of long-running behaviors. This points to 2026 as the year agentic AI moves from hype to reliable digital coworkers. (Based on ecosystem activity and framework evolutions observed in the monitoring window)
Multimodal Foundation Model Trends and Efficiency Gains
Frontier efforts increasingly focus on native multimodal training rather than bolted-on adapters, enabling seamless token fusion across text, vision, and audio. Efficiency innovations, such as sparse activation or optimized MoE routing, allow larger effective parameter counts without proportional compute explosion.
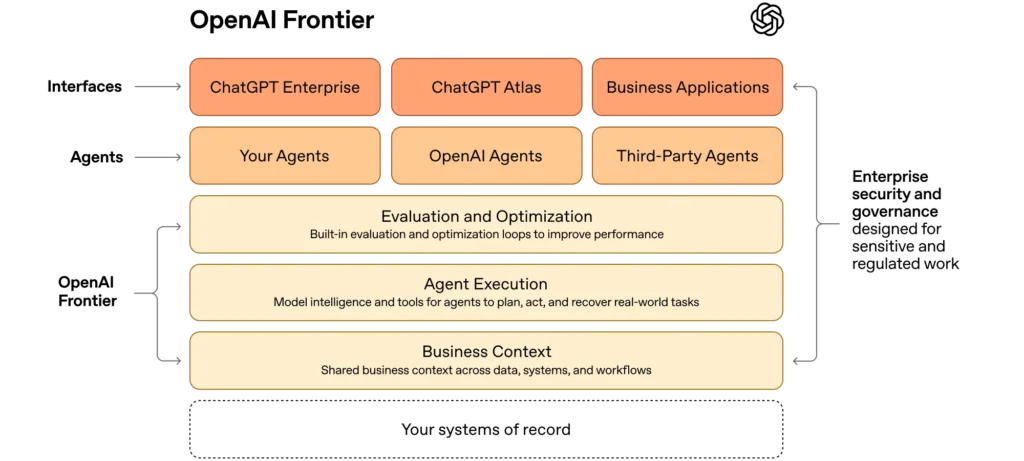
These models power breakthroughs in video understanding, real-time world simulation, and reasoning over mixed inputs. Real-world applications accelerate in creative tools, autonomous robotics planning, and data analysis. Prospects are bright for consumer-accessible frontier performance, but hurdles include data quality bottlenecks and the need for advanced alignment techniques. The trajectory suggests rapid closing of gaps between closed and open models. (Informed by ongoing 2026 benchmark and architecture discussions)
Open-Source and Specialized Model Ecosystem Updates
Activity in open-weight releases, particularly for coding and agentic tasks, continues to bolster accessibility. Models optimized for tool use and multi-turn workflows empower developers to build custom agents without massive infrastructure. This democratizes frontier capabilities and fosters rapid innovation cycles through community fine-tuning.
Impacts include faster prototyping in research and industry, with challenges around maintaining safety in open ecosystems. Forward implications: hybrid closed-open strategies will dominate, accelerating overall progress while distributing capabilities globally.
In summary, the past 24 hours reinforce that 2026’s AI advancements center on unification (omni-models), autonomy (agentic systems), and efficiency. These developments carry profound implications for productivity, creativity, and discovery.
Stay tuned for more daily cutting-edge AI updates.
The images used in this article are sourced from publicly available channels on the internet. They are used solely for the purposes of news commentary, visual illustration, and explanatory reference, and do not constitute commercial use. The author of this article does not own the copyright to these images and makes no claim to any rights over them. If any copyright issues arise regarding these images, please contact the article’s author, and we will promptly address the matter or remove the relevant content.