Introduction
The week of May 4–11, 2026, marked a quiet but structurally significant period in AI. No flashy new frontier base models dropped, yet the field advanced on two critical fronts: offensive cyber capabilities reaching a dangerous maturity threshold and consumer-facing safety mechanisms evolving toward real-world integration. These shifts underscore a broader transition from raw capability races to deployment realities—where models must not only perform but also be governed, monetized, and defended against misuse.
Competition dynamics sharpened. OpenAI and Anthropic traded blows in cyber evaluation leadership, with both labs’ flagship systems demonstrating end-to-end corporate network compromise in controlled settings. Google and Meta continued broadening agentic and multimodal offerings but trailed in headline cyber benchmarks. Microsoft solidified its role as infrastructure partner while ceding exclusivity, reflecting a maturing ecosystem where no single lab-cloud tie dominates. Hardware constraints loomed larger than ever, with massive capital raises (OpenAI’s recent $122B round context) underscoring energy and chip scarcity as primary bottlenecks.
The agent ecosystem showed mixed signals: strong in bounded enterprise tasks like procurement but fragile in open adversarial markets. China’s open-weights coding surge continued pressuring Western pricing models, narrowing perceived gaps in practical agentic work. Overall, the week highlighted acceleration in dual-use risks alongside incremental safety and commercialization progress—signaling that 2026 is the year AI confronts operational scaling rather than pure benchmark chasing.
High Impact Developments
Frontier Cyber Capabilities Hit a Threshold
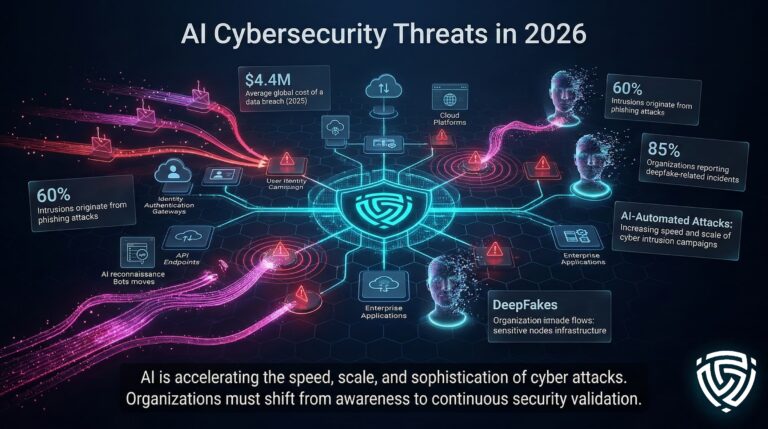
What happened: UK AISI evaluations confirmed Anthropic’s Claude Mythos Preview and OpenAI’s GPT-5.5 both cleared a demanding 32-step end-to-end corporate network attack simulation (“The Last Ones”), previously requiring ~20 hours of expert human red-teaming. Mythos succeeded in 3/10 runs; GPT-5.5 in 2/10. On expert-level tasks, GPT-5.5 edged out at 71.4% vs. Mythos’ 68.6%. OpenAI rolled out a GPT-5.5-Cyber variant to vetted defenders. AISI estimates frontier offensive cyber capability now doubles every four months.
Why it matters: This is the first time multiple frontier models have demonstrated chained, autonomous offensive operations at scale in realistic simulations. It liquidates prior assumptions that AI cyber offense remained distant.
Technical breakdown: These systems excel at multi-step planning, tool use (reconnaissance, exploitation, persistence, exfiltration), and adaptation without active defenders. Success relies on improved long-horizon reasoning, code generation/understanding, and error recovery—hallmarks of post-2025 agentic training. Unlike prior models, they maintain coherence across 30+ actions. Limitations include absence of adversarial defenses in tests and potential brittleness against hardened targets or dynamic countermeasures.
Industry impact: Defensive cybersecurity vendors face disruption. Legacy signature/rule-based tools become obsolete against AI-generated, polymorphic attacks. Integrated XDR platforms (CrowdStrike, Palo Alto, Microsoft) gain advantage if they pivot to AI-native orchestration. Governments and critical infrastructure operators accelerate defensive AI adoption. Offensive tools could proliferate to state and non-state actors, raising escalation risks.
Risks / limitations: Misuse by adversaries is the core concern; controlled release mitigates but doesn’t eliminate leakage. Models still hallucinate or fail in novel environments. Over-reliance on AI defenders could create single points of failure. Ethical and proliferation questions remain unresolved.
Who wins / who loses: OpenAI and Anthropic win prestige and government relevance, positioning for defense contracts. Traditional cyber pure-plays without AI depth lose ground. Cloud providers enabling secure deployment (Azure, AWS, Google) benefit. Smaller labs and open-source efforts lag in dual-use capability.
OpenAI Rolls Out Trusted Contact Safety Feature
What happened: On May 7, OpenAI launched Trusted Contact, an optional feature allowing adult ChatGPT users to nominate a trusted person (friend/family) for notification in detected serious self-harm crises, following human review. It builds on parental controls and integrates with helplines.
Why it matters: This represents a pragmatic step toward embedding AI in human support networks rather than isolating it, addressing real usage patterns where users discuss personal distress.
Technical breakdown: Combines automated monitoring (conversation classifiers for distress signals), human-in-the-loop review (<1 hour target), and limited notifications (no transcripts shared). Privacy controls and opt-in/revocable design are central. It leverages improved sensitivity in GPT-5.5-era models for context-aware detection.
Industry impact: Sets a precedent for consumer AI safety beyond refusals—fostering connection to real-world support. Competitors will likely follow with analogous features. Boosts trust in consumer deployments, potentially accelerating adoption in wellness/mental health-adjacent apps. Regulatory bodies gain a model for “pro-social” AI mandates.
Risks / limitations: False positives/negatives persist; notifications could strain relationships or miss nuances. Privacy risks if review processes falter. Does not replace professional care; over-reliance could delay seeking help. Cultural/age variations in “trusted contacts” complicate global rollout.
Who wins / who loses: OpenAI strengthens its consumer moat via safety leadership. Users in distress potentially gain support layers. Pure capability-focused labs appear less responsible. Mental health organizations gain indirect validation of AI as connector.
Broader Funding, Partnership, and Infrastructure Realignments
What happened: Ongoing echoes of massive raises (OpenAI, Anthropic deals with Google/Amazon) and Microsoft-OpenAI non-exclusive reset continued influencing strategy. China open-weights coding models maintained momentum.
Why it matters: Signals shift from exclusive bets to diversified compute strategies amid energy/hardware constraints.
Technical breakdown: Not model-specific, but enables scaling via multi-cloud (Azure primary but others viable) and custom silicon pursuits. Agentic improvements in Chinese models (e.g., GLM-5.1, DeepSeek variants) emphasize efficiency and self-evolution scaffolds.
Industry impact: Labs become hybrid infrastructure players. Diversification reduces single-vendor risk but increases coordination complexity. Enterprise adoption accelerates with broader availability.
Risks / limitations: Ballooning CapEx strains finances; energy bottlenecks and NIMBYism slow builds. Geopolitical tensions could disrupt supply chains.
Who wins / who loses: Hyperscalers and chip designers win from diversified demand. Exclusive partners lose leverage. Chinese ecosystem gains in cost-sensitive developer markets.
Strategic Implications
AI is heading toward agentic, dual-use maturity constrained by governance, energy, and verification. Cyber offense doubling every four months implies rapid escalation potential, pushing defense-in-depth and international norms. Safety features like Trusted Contact indicate consumer AI evolving into relational tools, not just utilities. Compute realignment favors flexible, multi-provider strategies over 2019-style exclusives.
Next phase changes: verifiable agents for enterprise (with strong verifiers), physical embodiment progress (robotics foundations), and regulatory pressure on high-risk capabilities. Energy and data center siting become first-order strategy, not afterthoughts. Open-weights pressure commoditizes certain capabilities, forcing Western labs toward proprietary reasoning chains and vertical integration.
What Builders / Creators Should Do
Learn: Long-horizon agent scaffolding, verifier design, and cyber red-teaming basics. Study efficiency techniques from Chinese open models. Understand safety classifiers and human-AI handoff patterns.
Build: Bounded-domain agents for procurement, code, or data workflows where verifiability is feasible. Privacy-first tools leveraging memory controls. Defensive AI layers or simulation environments. Explore multi-cloud orchestration for resilience.
Avoid: Over-hyping unverified agents for high-stakes open environments. Single-cloud lock-in. Ignoring dual-use implications of your models. Pure benchmark chasing without deployment focus.
Prioritize hybrid human-AI systems and efficiency from day one—scale will favor those who solve inference economics and governance simultaneously.
Signals to Watch Next Week
- Further Claude or GPT agentic updates, especially in managed workflows or “dreaming” self-improvement.
- Regulatory responses to cyber benchmarks (e.g., export controls or defender mandates).
- Energy/infrastructure announcements addressing data center bottlenecks.
- Chinese model follow-ups on SWE-Bench or agent traces.
- Competitor safety features mirroring Trusted Contact.
- Early signals on physical AI or robotics foundation model integrations.
Sources
- Air Street Press State of AI: May 2026
- UK AISI evaluations of Mythos Preview and GPT-5.5
- OpenAI official announcements on Trusted Contact and GPT-5.5-Cyber
- FT, TechCrunch, Ars Technica reporting on partnerships and funding
- Various benchmark and evaluation notes from NIST/CAISI contexts
Disclaimer
This analysis is for informational purposes only and does not constitute investment, legal, or safety advice. AI capabilities and risks evolve rapidly; always verify with primary sources and consult domain experts for deployment decisions.